Ядро - интелИнтересно ядро какое. Может же быть что-то как Raspberry Pi.
MQTT работает поверх UDP, но в этом случае думаю и брокер и клиенты должны быть в одной сети.
MQTT в широко применяемых брокерах как правило использует TCP
но есть решения с использованием UDP которые доказали свое превосходство над классикой особенно для встраиваемых систем.
---------------------
Поясню относительно теста.
Посмотрите внимательно на то, что я написал:
Информация к размышлению:
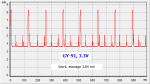
делал тест системы сервер-клиент UDP для "системы умный дом" .
Сервер с одним ядром успевает обрабатывать до 40 тысяч пакетов в секунду.
По UDP можете подключать любое количество, так как нет надобности устанавливать соединение и держать его открытым.
Трафик минимум в два раза меньше.
Обратите внимание - я не написал что это wifi
я не написал что это ESP
Тест решал задачу проверки пропускной способности виртуального малобюджетного сервера
это сервер для создания системы умного дома с выходом в интернет и затратами на его содержание в пределах 10 долларов в год.
а также возможность защиты от DDOS- атак.
В итоге мне удалось сделать такой сервер с указанной пропускной способностью.
-------------------
На форуме есть такой пердун -pvvx
так как он тридцать лет ковыряется в чипах,
то считает себя всезнающим в любых вопросах и всевидящим в мировом масштабе.
-------------------
Поэтому он лезет как глист во все дырки со своими нравоучениями
На форуме он как петух в курятнике.
Если не затопчет очередного дуринщика, то чувствует себя плохо.
----------------------
Рекомендую фильтровать его высказывания,
так как все, что не касается его измерений тока или напряжения ,
обычно является его самохвальством и словесным поносом.