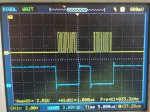
spi_master_write работает а все потоковые как interrupt так dma - нет.
Код:
// SPI0 (S0)
#define SPI0_MOSI PC_2
#define SPI0_MISO PC_3
#define SPI0_SCLK PC_1
#define SPI0_CS PC_0
volatile uint8_t MasterRxDone, MasterTxDone;
spi_t spi_master;
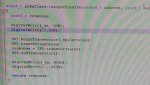
void master_tr_done_callback(void *pdata, SpiIrq event)
{
switch(event){
case SpiRxIrq:
//DBG_8195A("Master RX done!\n");
MasterRxDone = 1;
break;
case SpiTxIrq:
//DBG_8195A("Master TX done!\n");
MasterTxDone = 1;
break;
default:
DBG_8195A("unknown interrput evnent!\n");
}
}
/* выбор устройства
* ss_code - код для дешифратора,
*/
void spi0_slave_select(const uint8_t ssn)
{
uint8_t ss_code;
switch (ssn)
{
case 0:
ss_code = 127;
break;
case 1:
ss_code = ~1;
break;
case 2:
ss_code = ~(1<<4);
break;
case 3:
ss_code = ~((1<<4) | 1);
break;
case 4:
ss_code = ~(1<<5);
break;
default :
ss_code = 127;
}; // switch
// код CS_x
// допустимый диапазон cs_code 1...0xff, если 0 - SPI зависает
// *(volatile uint32_t*)(SSI0_REG_BASE + REG_DW_SSI_SER) = ss_code; // задаем код слэйва (лучше использовать HAL_SSI_WRITE32())
HAL_SSI_WRITE32(0, REG_DW_SSI_SER, ss_code);
}
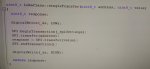
static void spi0_hw_configure(void)
{
char* buff;
int32_t length;
int32_t c;
ConfigDebugInfo |= _DBG_SSI_;
spi_init(&spi_master, SPI0_MOSI, SPI0_MISO, SPI0_SCLK, SPI0_CS); // CS заданный тут нигде не используется
spi_format(&spi_master, 16, 0, 0);
spi_frequency(&spi_master, 200000);
// нужен только чтобы включить SPI0_MULTI_CS_EN в регистре SPI_MUX_CTRL,
// число любое от 2 до 7
//spi_slave_select(&spi_master, 2);
buff = pvPortMalloc(256);
c=0;
do {
//spi0_slave_select(c & 7);
MasterTxDone = 0;
//length= spi_master_write(&spi_master, c);
spi_irq_hook(&spi_master, master_tr_done_callback, (uint32_t)&spi_master);
spi_master_write_stream(&spi_master, buff, 160);
while(MasterTxDone == 0) {
//wait_ms(10);
}
rtl_printf("Master write: %d\n", c);
c++;
}
while (1);
free(buff);
}
Код:
===== Enter SRAM-Boot 1 ====
CPU CLK: 83333333 Hz, SOC FUNC EN: 0x20211113
Img Sign: RTKWin, Go @ 0x1000607d
===== Enter Image: tp6_rtl ====
[SSI Inf]SystemClock: 166666666
[SSI Inf]MaxSsiFreq : 20833333
[SSI Inf]ssi_peri: 2049, ssi_idx: 0, ssi_pinmux: 1
[SSI Inf]spi_frequency: Set SCLK Freq=200320
Init Heap Region: 0x10003000[12288]
Init Heap Region: 0x100460f8[171784]
[SSI Inf]HalSsiIntWriteRtl8195a: Idx=0, RxData=0x10003008, Len=0xa0