Переделал на ассемблере
Код:
Дизассеблер:
Результаты
Использование спираченного компилера в открытом проекте абсолютно неприемлемо.
У xtensa компилятора есть бесплатные варианты ?
Для разных файлов наверно объединяться не будут.
Обсуждение кривизны UDK не для этой темы.
Давайте обсудим разницу во времени записи для 8 и 16 регистров.
Код:
Код:
oid __attribute__((optimize("O2"))) write_test(uint32_t i)
{
uint32_t j=0;
uint32_t t1, t2;
uint32_t* ptr =(uint32_t *)SPI_W0(HSPI);
ets_uart_printf("\n--------\n");
os_delay_us(100000);
do
{
ets_uart_printf("\twithout MEMW\n");
os_delay_us(100000);
__asm__ __volatile__("memw" : : : "memory");
ets_intr_lock();
GET_CCOUNT(t1);
//t1=get_ccount();
__asm__ __volatile__("S32I.N %0, %1, 0 \n\t"
"S32I.N %0, %1, 4 \n\t"
"S32I.N %0, %1, 8 \n\t"
"S32I.N %0, %1, 12 \n\t"
"S32I.N %0, %1, 16 \n\t"
"S32I.N %0, %1, 20 \n\t"
"S32I.N %0, %1, 24 \n\t"
"S32I.N %0, %1, 28 \n\t"
: : "r"(j), "r"(ptr));
//__asm__ __volatile__("memw" : : : "memory");
GET_CCOUNT(t2);
//t2=get_ccount();
ets_intr_unlock();
ets_uart_printf(" 8 writes: time= %d\n", calcdelta(t1, t2));
os_delay_us(100000);
__asm__ __volatile__("memw" : : : "memory");
ets_intr_lock();
GET_CCOUNT(t1);
//t1=get_ccount();
__asm__ __volatile__("S32I.N %0, %1, 0 \n\t"
"S32I.N %0, %1, 4 \n\t"
"S32I.N %0, %1, 8 \n\t"
"S32I.N %0, %1, 12 \n\t"
"S32I.N %0, %1, 16 \n\t"
"S32I.N %0, %1, 20 \n\t"
"S32I.N %0, %1, 24 \n\t"
"S32I.N %0, %1, 28 \n\t"
"S32I.N %0, %1, 32 \n\t"
"S32I.N %0, %1, 36 \n\t"
"S32I.N %0, %1, 40 \n\t"
"S32I.N %0, %1, 44 \n\t"
"S32I.N %0, %1, 48 \n\t"
"S32I.N %0, %1, 52 \n\t"
"S32I.N %0, %1, 56 \n\t"
"S32I.N %0, %1, 60 \n\t"
: : "r"(j), "r"(ptr));
//__asm__ __volatile__("memw" : : : "memory");
GET_CCOUNT(t2);
//t2=get_ccount();
ets_intr_unlock();
ets_uart_printf("16 writes: time= %d\n", calcdelta(t1, t2));
os_delay_us(100000);
ets_uart_printf("\twith MEMW\n");
os_delay_us(100000);
__asm__ __volatile__("memw" : : : "memory");
ets_intr_lock();
GET_CCOUNT(t1);
//t1=get_ccount();
__asm__ __volatile__("S32I.N %0, %1, 0 \n\t"
"S32I.N %0, %1, 4 \n\t"
"S32I.N %0, %1, 8 \n\t"
"S32I.N %0, %1, 12 \n\t"
"S32I.N %0, %1, 16 \n\t"
"S32I.N %0, %1, 20 \n\t"
"S32I.N %0, %1, 24 \n\t"
"S32I.N %0, %1, 28 \n\t"
: : "r"(j), "r"(ptr));
__asm__ __volatile__("memw" : : : "memory");
GET_CCOUNT(t2);
//t2=get_ccount();
ets_intr_unlock();
ets_uart_printf(" 8 writes: time= %d\n", calcdelta(t1, t2));
os_delay_us(100000);
ptr=(uint32_t *)SPI_W0(HSPI);
__asm__ __volatile__("memw" : : : "memory");
ets_intr_lock();
GET_CCOUNT(t1);
//t1=get_ccount();
__asm__ __volatile__("S32I.N %0, %1, 0 \n\t"
"S32I.N %0, %1, 4 \n\t"
"S32I.N %0, %1, 8 \n\t"
"S32I.N %0, %1, 12 \n\t"
"S32I.N %0, %1, 16 \n\t"
"S32I.N %0, %1, 20 \n\t"
"S32I.N %0, %1, 24 \n\t"
"S32I.N %0, %1, 28 \n\t"
"S32I.N %0, %1, 32 \n\t"
"S32I.N %0, %1, 36 \n\t"
"S32I.N %0, %1, 40 \n\t"
"S32I.N %0, %1, 44 \n\t"
"S32I.N %0, %1, 48 \n\t"
"S32I.N %0, %1, 52 \n\t"
"S32I.N %0, %1, 56 \n\t"
"S32I.N %0, %1, 60 \n\t"
: : "r"(j), "r"(ptr));
__asm__ __volatile__("memw" : : : "memory");
GET_CCOUNT(t2);
//t2=get_ccount();
ets_intr_unlock();
ets_uart_printf("16 writes: time= %d\n\n", calcdelta(t1, t2));
os_delay_us(100000);
}
while (--i);
ets_uart_printf("\n--------\n");
}
Код:
__asm__ __volatile__("memw" : : : "memory");
40100f9e: 0020c0 memw
ets_intr_lock();
40100fa1: fd2c01 l32r a0, 40100454 <ets_timer_arm_new+0xd0>
40100fa4: 0000c0 callx0 a0
GET_CCOUNT(t1);
40100fa7: 03ea30 rsr.ccount a3
//t1=get_ccount();
__asm__ __volatile__("S32I.N %0, %1, 0 \n\t"
40100faa: 0128 l32i.n a2, a1, 0
40100fac: 02c9 s32i.n a12, a2, 0
40100fae: 12c9 s32i.n a12, a2, 4
40100fb0: 22c9 s32i.n a12, a2, 8
40100fb2: 32c9 s32i.n a12, a2, 12
40100fb4: 42c9 s32i.n a12, a2, 16
40100fb6: 52c9 s32i.n a12, a2, 20
40100fb8: 0662c2 s32i a12, a2, 24
40100fbb: 72c9 s32i.n a12, a2, 28
"S32I.N %0, %1, 20 \n\t"
"S32I.N %0, %1, 24 \n\t"
"S32I.N %0, %1, 28 \n\t"
: : "r"(j), "r"(ptr));
//__asm__ __volatile__("memw" : : : "memory");
GET_CCOUNT(t2);
40100fbd: 03ead0 rsr.ccount a13
Код:
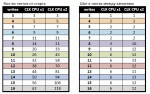
--------
without MEMW
8 writes: time= 17
16 writes: time= 70
with MEMW
8 writes: time= 47
16 writes: time= 96
without MEMW
8 writes: time= 17
16 writes: time= 70
with MEMW
8 writes: time= 47
16 writes: time= 96
without MEMW
8 writes: time= 17
16 writes: time= 70
with MEMW
8 writes: time= 47
16 writes: time= 96
without MEMW
8 writes: time= 17
16 writes: time= 70
with MEMW
8 writes: time= 47
16 writes: time= 96
--------Чем предлагаете компилить после выкидывания UDK ????Выкинуть компилятор UDK на помойку.
Использование спираченного компилера в открытом проекте абсолютно неприемлемо.
У xtensa компилятора есть бесплатные варианты ?
Наверно это потому что смещение задается в коде. Было бы в регистре - все было бы в порядке. А оптимизатор на уровне Arm процессоров никто писать не хочет.Он ваши *ptr++= i раскладывает на load в регистр 32-х битный адрес по смещению, потом запись по этому регистру со смещением ноль. По другому он не умеет. И вообще не умеет работать со смещениями - адрес в регистре + смещение. Только нулевое смещение.
У меня константы объединяются, во всяком случае в пределах одного исходника. Четко вижу по дизассемблеру что (uint32_t *)SPI_W0(HSPI) берется из обработчика прерывания где эта константа была ранее задана.И то что он наплодил в _stext констант - они не объединяются, т.к. каждая эксклюзивная.
Для разных файлов наверно объединяться не будут.
Обсуждение кривизны UDK не для этой темы.
Давайте обсудим разницу во времени записи для 8 и 16 регистров.
")