пояснение к приведенным ранее картинкам. Перевод гугл.
---------------------------------------
Мы предлагаем HiFi-GAN, который обеспечивает более высокую вычислительную эффективность и качество выборки, чем AR или модели на основе потоков.
Поскольку речевой звук состоит из синусоидальных сигналов с различными периодами, моделирование периодических паттернов имеет значение для создания реалистичного речевого звука.
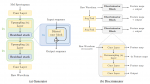
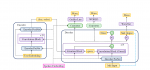
Поэтому мы предлагаем дискриминатор, состоящий из небольших поддискриминаторов, каждый из которых получает только определенные периодические части необработанных сигналов.
Эта архитектура является основой нашей модели, успешно синтезирующей реалистичный речевой звук.
Поскольку мы извлекаем разные части звука для дискриминатора, мы также разрабатываем модуль, который размещает несколько остаточных блоков,
каждый из которых параллельно наблюдает паттерны различной длины, и применяем его к генератору.
HiFi-GAN имеет более высокий балл MOS, чем лучшие общедоступные модели, WaveNet и WaveGlow.
Он синтезирует звук речи человеческого качества на частоте 3,7 МГц на одном графическом процессоре V100.
Далее мы показываем универсальность HiFi-GAN для инверсии мел-спектрограммы невидимых динамиков и сквозного синтеза речи.
Наконец, миниатюрная версия HiFi-GAN требует всего 0,92 млн параметров,
при этом превосходя лучшие общедоступные модели и самую быструю версию образцов HiFi-GAN в 13,44 раза быстрее,
чем в режиме реального времени на ЦП, и в 1186 раз быстрее, чем в режиме реального времени на одном устройстве.
Графический процессор V100 с качеством, сравнимым с авторегрессивным аналогом.
Наши аудио образцы доступны на демо-сайте
1, и мы предоставляем реализацию с открытым исходным кодом для воспроизводимости и будущей работы.

 github.com
github.com

 colab.research.google.com
colab.research.google.com